
长春seo:百度搜索引擎工作原理系列转自百度官方,不做任何过多注解。
今天,小小课堂网为大家带来的是转自百度官方《百度搜索引擎工作原理一:Spider抓取系统的基本框架》。长春seo希望对大家有所帮助。


Spider抓取系统的基本框架
互联网信息爆发式增长,如何有效的获取并利用这些信息是搜索引擎工作中的首要环节。数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做“spider”。例如我们常用的几家通用搜索引擎蜘蛛被称为:Baiduspdier、Googlebot、Sogou Web Spider等。
Spider抓取系统是搜索引擎数据来源的重要保证,如果把web理解为一个有向图,那么spider的工作过程可以认为是对这个有向图的遍历。从一些重要的种子 URL开始,通过页面上的超链接关系,不断的发现新URL并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型spider系统,因为每时 每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对spider过去抓取过的页面保持更新,维护一个URL库和页面库。
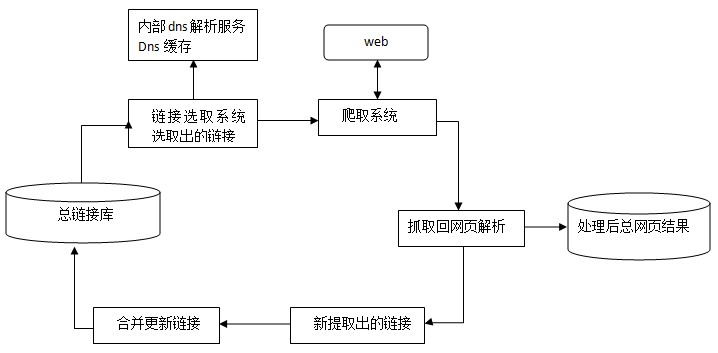
下图为spider抓取系统的基本框架图,其中包括链接存储系统、链接选取系统、dns解析服务系统、抓取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。Baiduspider即是通过这种系统的通力合作完成对互联网页面的抓取工作。
以上就是小小课堂网为大家带来的是转自百度官方《百度搜索引擎工作原理一:Spider抓取系统的基本框架》。长春seo感谢您的观看。SEO培训认准小小课堂!
所有文章均为小小课堂网原创。发布者:SEO免费培训教程,转转请注明出处:https://www.xxkt.org/5848
评论列表(1条)
小小课堂SEO自学网(https://www.xxkt.org/ ),全网营销SEO概念提出者,提供SEO培训、全站优化诊断、顾问咨询为主的SEO服务。分享SEO实战经验,新站快速排名,单页面排名和三方平台推广等技术。电子书营销、论坛发帖推广、电子邮件营销、新媒体运营等网络营销教程。